
Large Language Models (LLMs) have seen a surge in popularity due to their impressive results in natural language processing tasks, but there are still challenges to be addressed. Prompting in the question is a solution for some of them. Here, we present PIQARD, an open-source Python library that allows researchers to experiment with prompting techniques and information retrieval and combine them with LLMs. This library includes pre-implemented components and also allows users to integrate their own methods.
PIQARD is an open-source Python library that allows researchers to experiment with prompting techniques and information retrieval and combine them with LLMs. This library includes pre-implemented components and also allows users to integrate their own methods. Following schema shows the three main components of PIQARD and how they interact with each other.
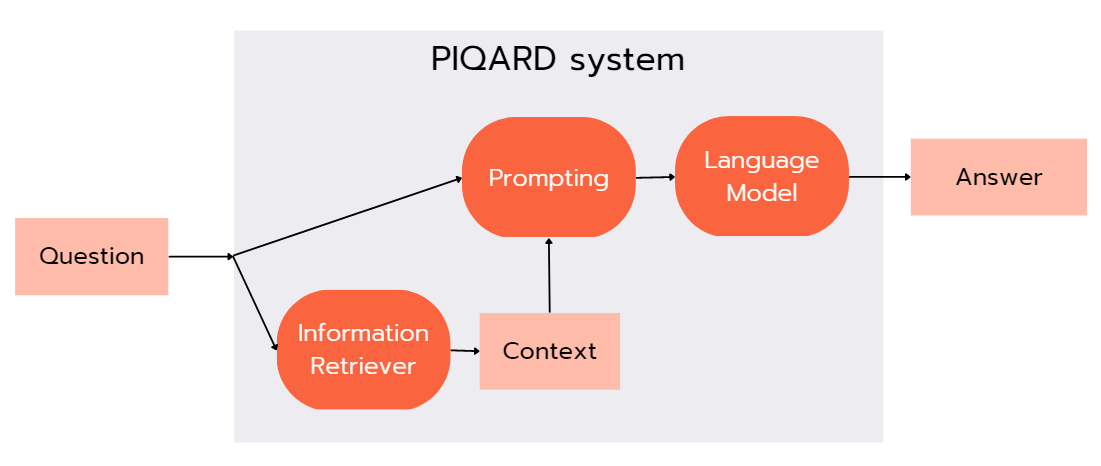
Question given by user is first processed by the Information Retriver (IR) component, responsible for serching the provided local database or web sources for the most relevant documents. Then retrieved context is passed along with the question to the Prompting component. This component is responsible for generating a specified prompt that will contain the question and the context. Finally, the Large Language Model component is used to generate the answer to the question, which is based on the previously prepared prompt.
The system has the ability to utilize language models that are hosted remotely and accessed through an API, in addition to ones that are deployed locally. In the experiments that were conducted, only language models that are easily available, such as open-source Bloom 176B and Cohere xlarge, were used. However, other language models that are more commercially-oriented could also be utilized.
The information retrieval component of the system can access both remote and local resources. Remote resources can be accessed through APIs, while local resources can be deployed within the system and searched using semantic and lexical algorithms, thanks to Annoy, FAISS and BM25 libraries.
Prompting with in-context learning is a technique that allows to improve the performance of LLMs by providing a pattern containing instructions on the task along with examples of its solution. One of the basic prompt template is shown below:
Answer the question.
Q: What is the capital of Germany?
A: Berlin
Q: What is the capital of France?
A: Paris
Q: What is the capital of Poland?
A: As you may notice the prompt is divided into two parts. The first part is the instruction, which is the same for all questions and briefly describe the task. The second part is the list of examples, which is a pair of question and answer. The last example is left blank, so that the LLM can fill it with the answer to the question. Below we present a few examples of more complex prompts, which are also implemented in PIQARD.
Reasoning and Acting (ReAct)[1] is a technique that allows to improve the performance of LLMs by providing not only a pattern containing instructions on the task along with examples of its solution, but also a set of actions that the LLM could perform. Authors originally have proposed a set of actions that can be performed by the LLM, e.g. "Search", which is searching for a specific information in the database. Additionaly model can provide a reasoning followed by "Thought" and "Observation" mark. On the right we present an example of a prompt that uses ReAct technique and below is an example of use this technique with PIQARD.
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?
Thought 1: I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same.
Action 1: Search[Pavel Urysohn]
Observation: Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory.
Thought 2: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and find its type of work.
Action 2: Search[Leonid Levin]
Observation: Leonid Anatolievich Levin is a Soviet-American mathematician and computer scientist.
Thought 3: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work.
Action 3: Finish[yes]
...
--- N more examples ---
...
Question: {{question}}
Self-aware is based on a simple assumption that LLMs can answer some questions solely based on the learned knowledge from training data. Therefore, there is no need for additional information retrieval that could potentially introduce unnecessary bias by forcing the model to focus only on the narrow content provided by the IR module, especially for basic and trivial questions. Usually it should be used with other prompting techniques, e.g. ReAct. On the left we present an example of a prompt used for Self-aware technique and below is an example of use this technique with PIQARD.
For each input, determine if the answerer will need to access the internet to respond.
Statements or question of opinion do not require the internet, factual question or commands might.
In general, simple factual questions whose answers do not change over time can be answered without the internet access.
Questions that refer to current events, news, sports, websites that change frequently, etc. will require the internet access.
Questions that refer highly specific events that the answer may not have memorized also require the internet access.
If they do not need to access the internet, the answerer will respond with "No". If they do, rephrase the question in the form of search command.
Input: Hello, how are you?
Output: No
Input: What is the capital of France?
Output: No
Input: Who won the 2022 World Cup?
Output: Find the 2022 Would Cup winner
Input: What's your name?
Output: No
Input: What is the current temperature in Paris?
Output: Find the current temperature in Paris
Input: What is machine learning?
Output: No
Input: {{question}}
Output:
Chain of Thought[2] prompting is a special prepared prompt that contain not only examples of questions with their answers, but also a step-by-step thought process that the LLM should follow to answer the question. Therefore, the expected output of the model includes not only the final answer but also the generated sequence of steps that led to it. On the right we present an example of a prompt that uses Chain of Thought technique and below is an example of use this technique with PIQARD.
Given the following question, write the step-by-step thought process and provide an answer:
Question: What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought: Let’s think step by step. The eastern sector of Colorado orogeny extends
into the High Plains. High Plains rise in elevation from around 1,800 to
7,000 ft, so the answer is 1,800 to 7,000 ft.
Answer: 1,800 to 7,000 ft
...
--- N more examples ---
...
Question: {{question}}
Thought: Let's think step by step.
Below we present more advanced examples with PIQARD library and Web application, that are possible solutions for knowledge hallucination problem. This is the phenomenon of generating wrong answers with high confidence, even if it is not justyfied by any of training data.
The proposed system with Self-aware prompting technique provided a correct answer and sequence of steps, which were performed by the model. However, the answer generated by a simple language model query is incorrect. Moreover, whether it sounds positive or negative, there is no basis for it, as the training set could not contain information about the chatbot ChatGPT, which was created after the model was trained (November 30, 2022).
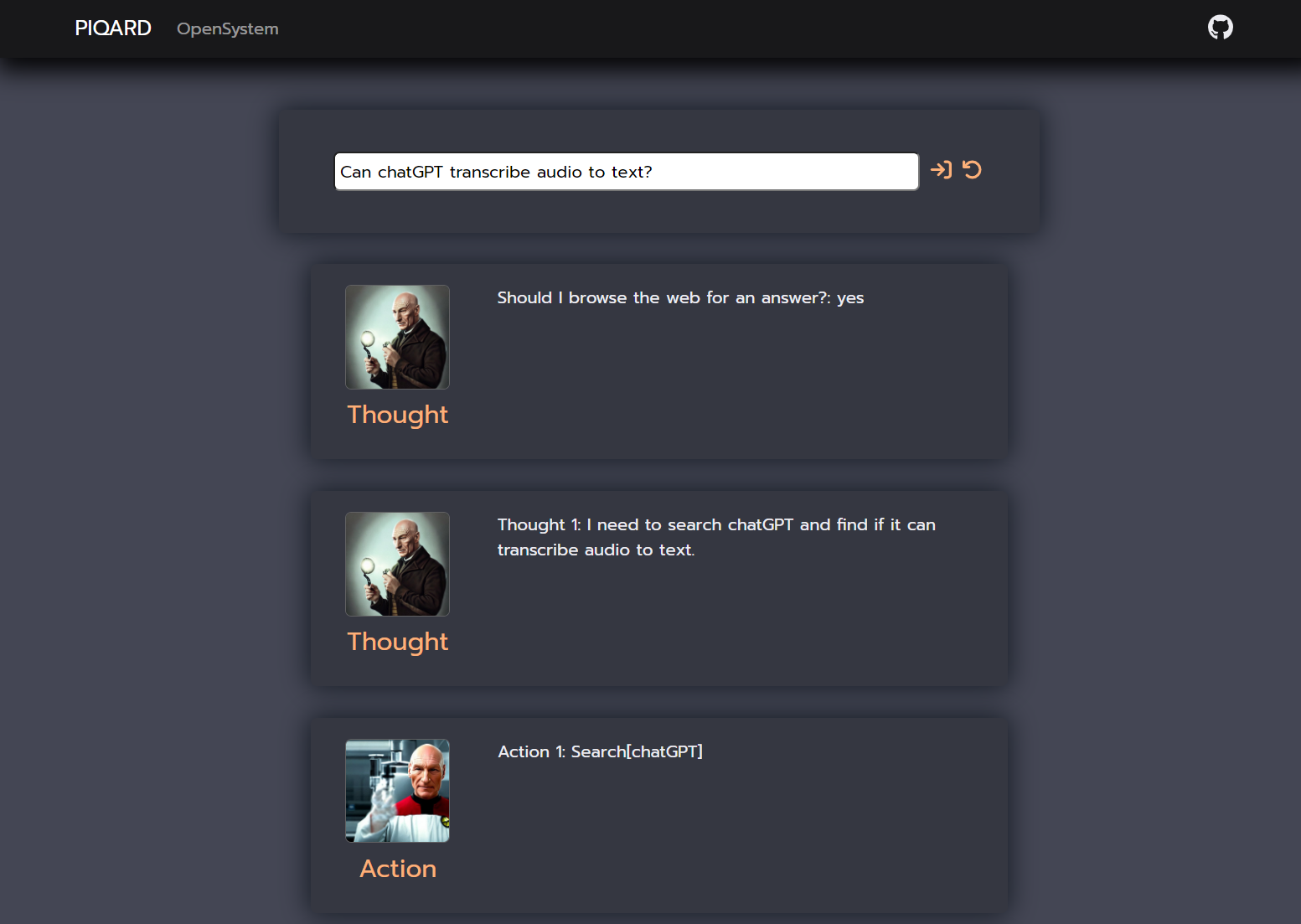
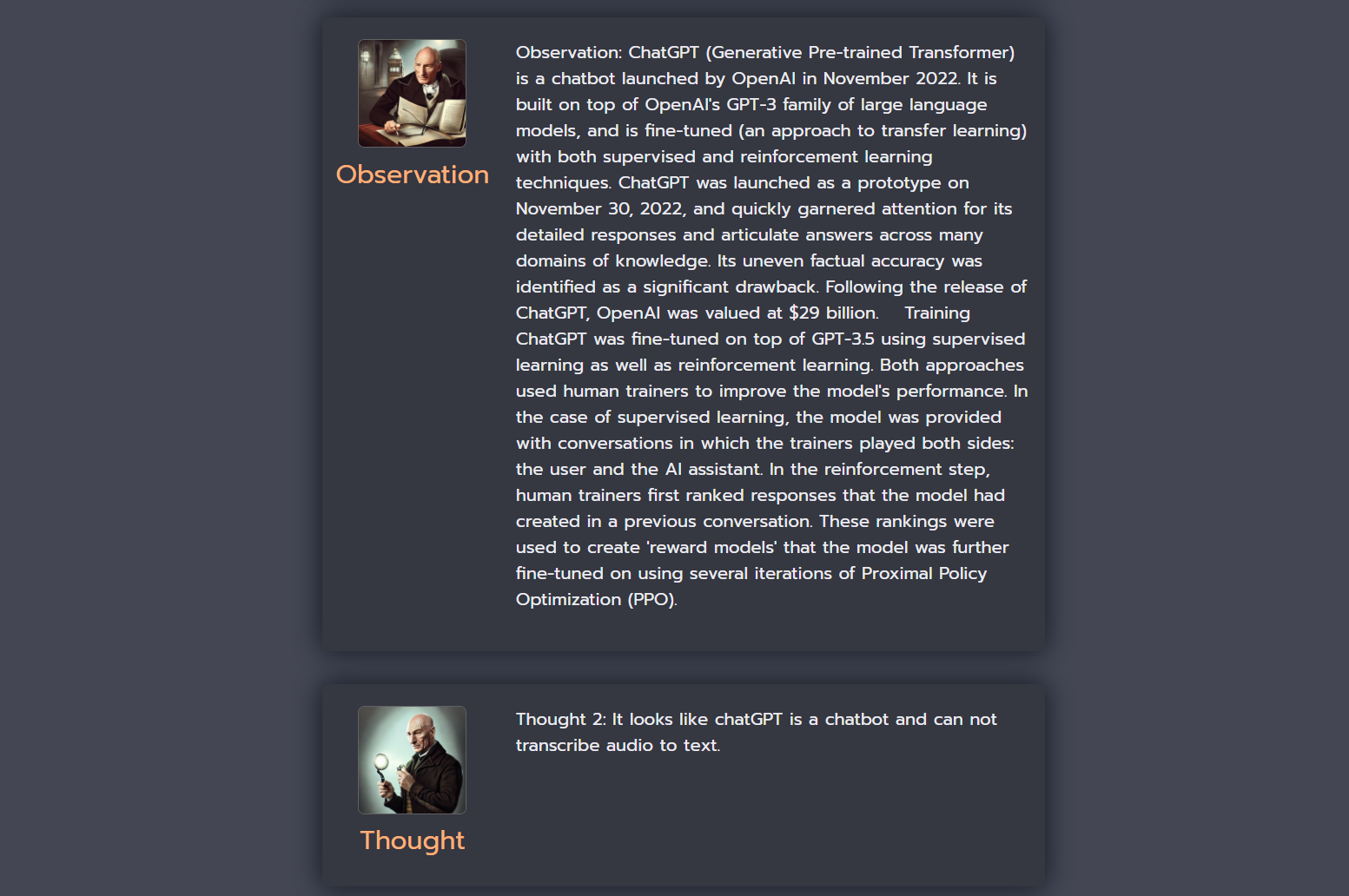
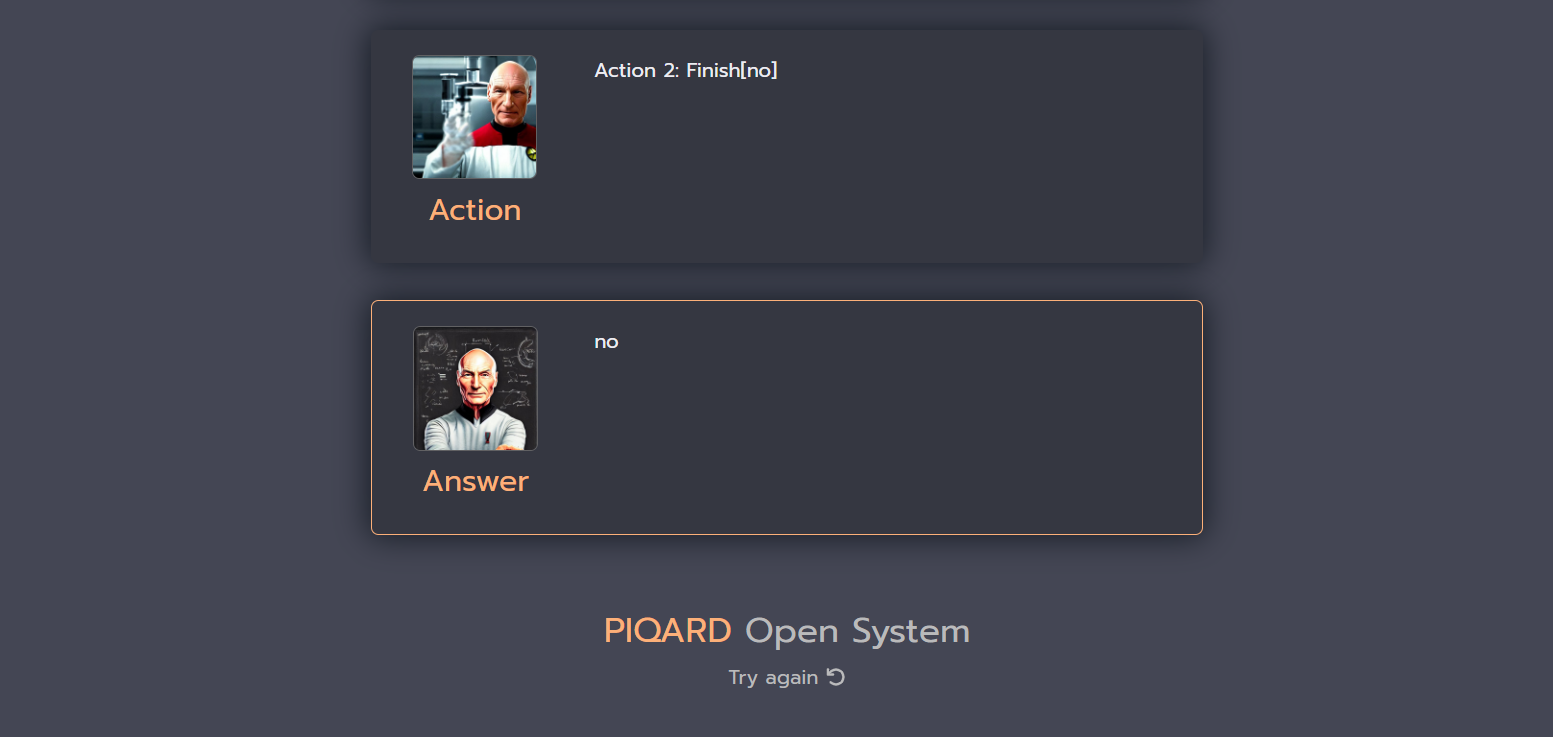
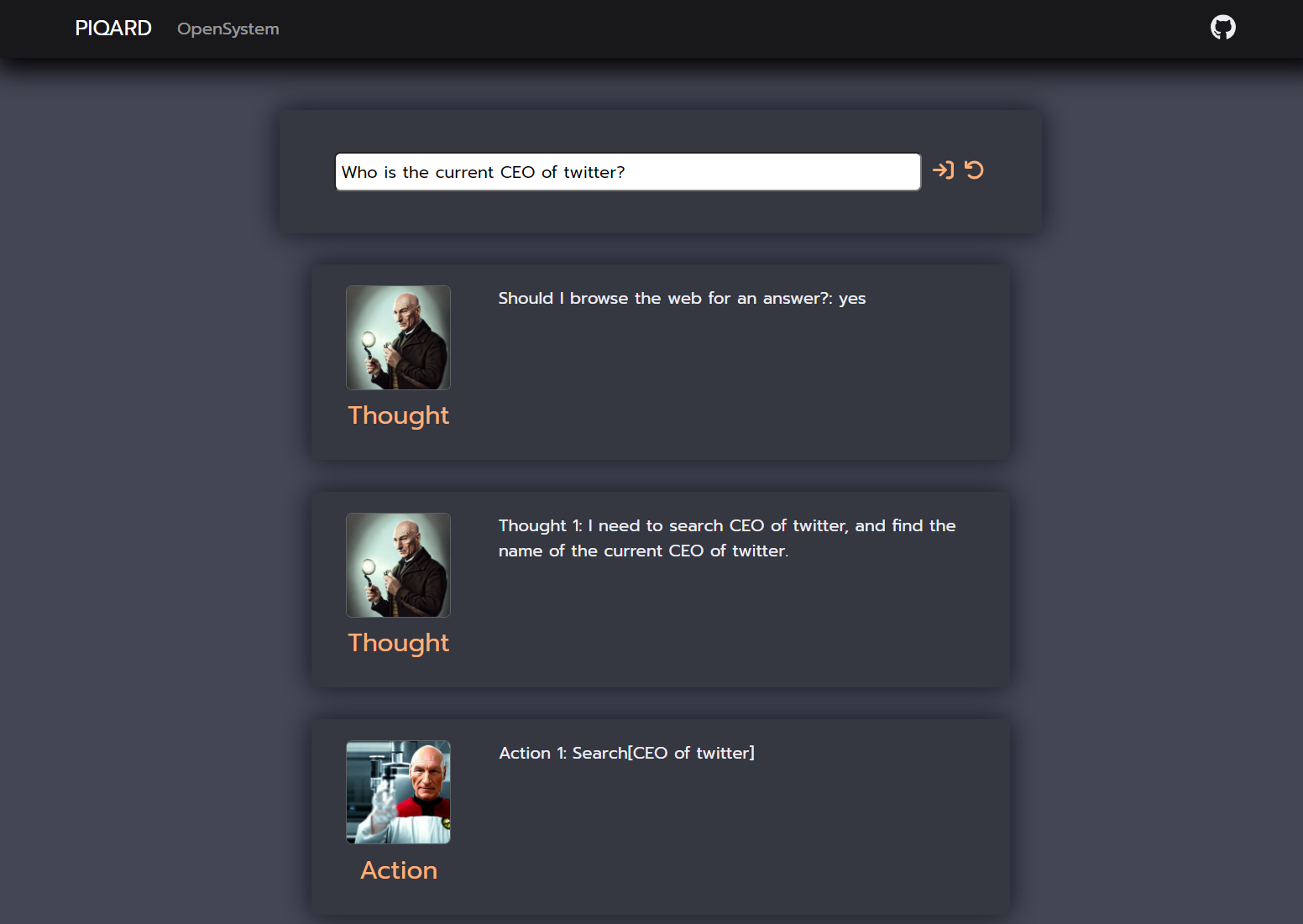
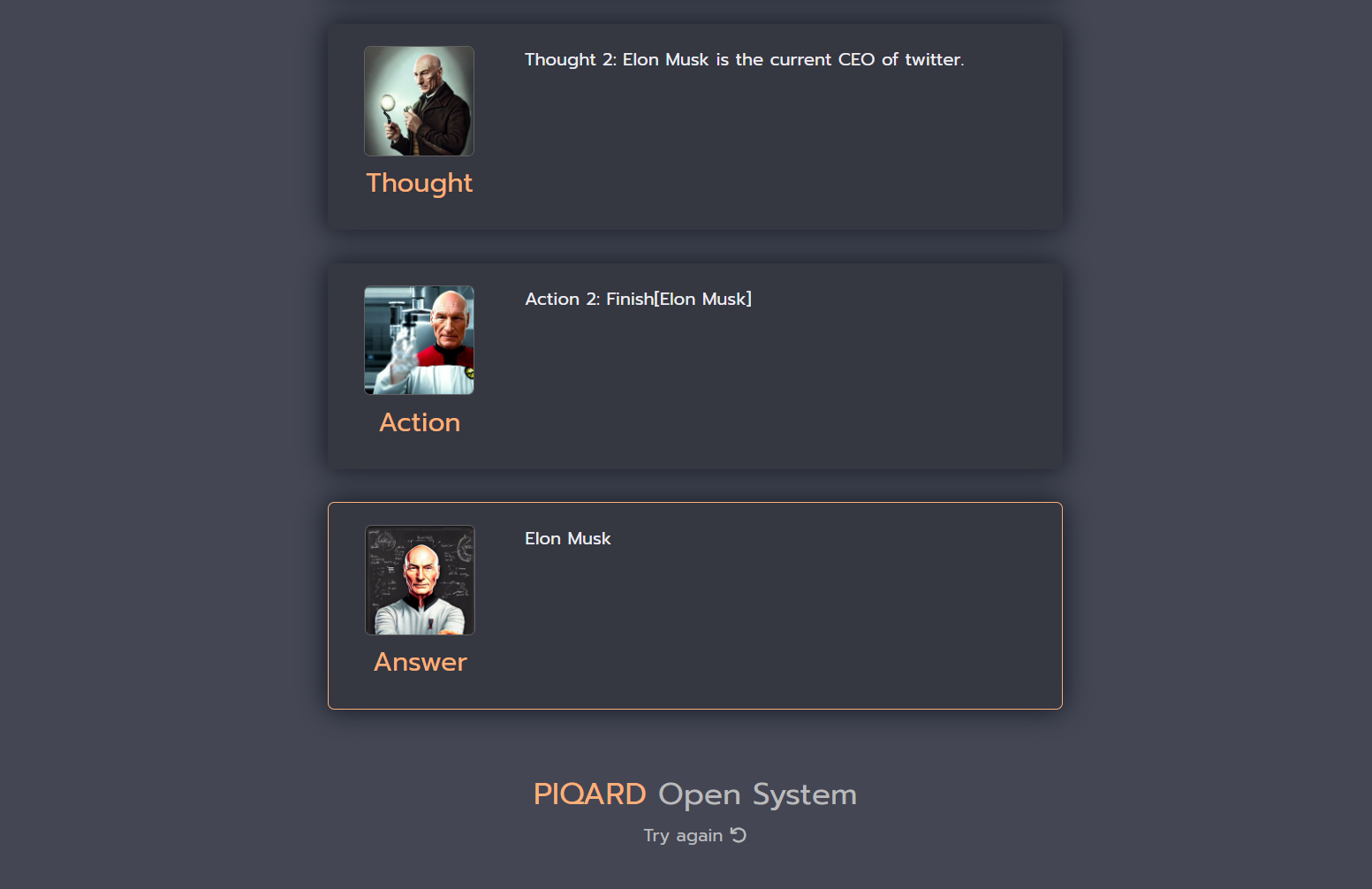
In this case the we have similar situation as in previous example. The proposed system with Self-aware prompting technique provided a correct answer and sequence of steps, which were performed by the model. However, the answer generated by a simple language model query is incorrect, but it is more plausible than in previous example, because Jack Dorsey was the CEO of Twitter before Elon Musk (end of 2023).

As part of our work, we conducted experiments aimed at testing the impact of certain prompting strategies on the quality of generated responses. We chose two benchmarks, OpenBookQA and HotpotQA, to conduct these experiments. The former consists of multiple-choice questions mainly focused on scientific facts, while the latter is composed of open-ended questions covering various domains. For both benchmarks, the authors provided sets of documents that we used to search for context for each test question. Below we present the results of several choosen experiments.
The aim of the experiment is to test the impact of the number of given task-solving examples in the prompt on the quality of generated responses. The prepared prompt templates for both benchmarks consist of a simple instruction and several examples of task-solving, with the variable parameter being the number of examples within the range of <0,5>.
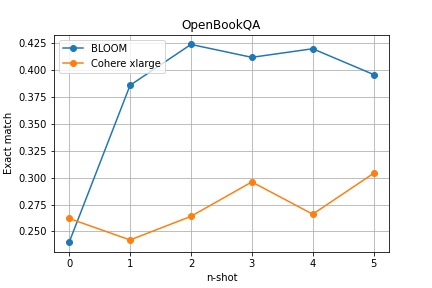
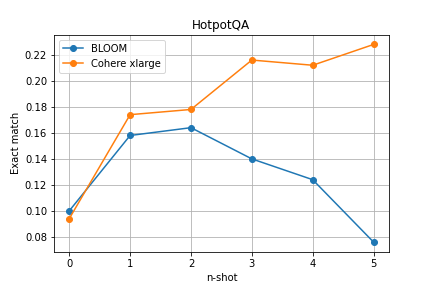
The results of the experiment indicate that even with just one example in the prompt, models are able to adapt their generated responses to the task, which increases their correctness. For the OpenBookQA benchmark, a significant improvement of around 15 percentage points was observed for the BLOOM model. It is worth noting that as the number of examples in the prompt increases, the model responses improve, however, the trend is not always monotonic, and may begin to fluctuate at a similar level at some point or even decrease. Interesting thing is that the Cohere model, despite having three times fewer parameters, achieved better results on the HotPotQA benchmark than Bloom thanks to prompting.
The aim of the experiment is to test the prompting strategy called Chain of Thought, which involves forcing the model to generate additional intermediate steps to the given response. The prepared prompt templates for both benchmarks consist of a simple instruction and several examples of task-solving, with the variable parameter being the number of examples within the list [1, 3, 5].
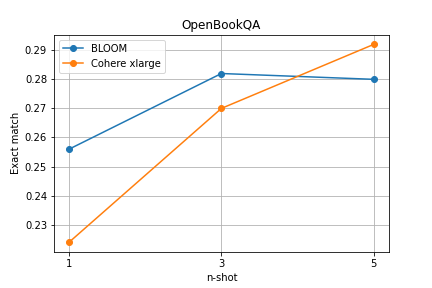
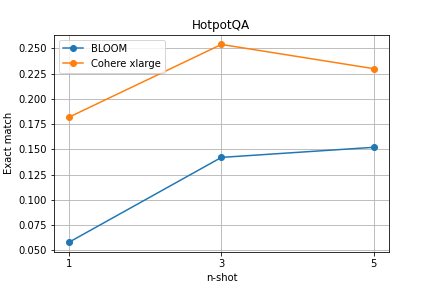
The results of the experiment once again indicate an improvement in the response generation performance of both models with an increase in the number of examples in the prompt. It is worth noting that in this case, for the HotpotQA benchmark, the Cohere xlarge model performed significantly better from the start, and impressively, for the OpenbookQA benchmark, despite initially worse results, it managed to surpass BLOOM with 5 examples.
The aim of the experiment is to test the impact of the order of examples on the results generated by language models. To conduct it, we prepared a template for the OpenBookQA benchmark, which consists of a simple instruction and five examples with one document provided as a fact, whose order was changed for each stage of the test.
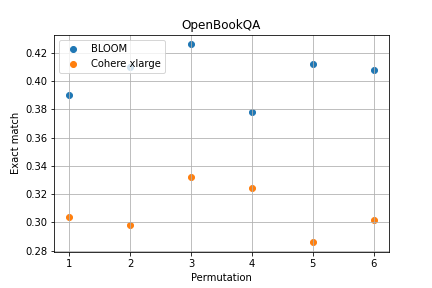
The results of the experiment indicate that the order of examples in the prompt has an impact on the response generated by the models. In our case, the difference is about 5%, which turns out to be significant given the maximum results presented.
In summary of the conducted experiments, we conclude that the use of prompting strategies can have a positive impact on the results achieved by natural language models.
However, they require the appropriate selection and preparation of a special prompt depending on the model and the characteristics of the questions.
This makes it impossible to determine a universal solution that will work in every case.
* The additional experiments beyond those presented above can be found in our engineering thesis. [ET]
[1] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, et al. React: Synergizing reasoning and acting in language models. https://arxiv.org/abs/2210.03629, 2022.
[2] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, et al. PaLM: Scaling language modeling with pathways. https://arxiv.org/abs/2204.02311, 2022.